Read on for that discussion, or jump straight to the project
homepage on GitLab which has a live
demo that runs in your web browser and other resources including
source code.
I updated fb-hitler a few years ago and never wrote
about it; today I spent some time to describe the new version, which is
implemented more robustly: now it’s a bootable image that runs in real mode, not
a Linux application.
Sometimes I find it useful to be able to quickly save a page to the Wayback Machine, often to be able to provide a stable link to a page that I don’t control- for instance if I’m pointing somebody to a document that describes something they’re asking about, then it’s nice to ensure that there will still be an archived copy if the original goes away.
While the landing page on web.archive.org has a “save now” form to quickly save a page given its URL, this is still more cumbersome than I’d like- it involves copying the desired URL, opening a new tab to web.
FPGAs are pretty cool pieces of hardware for tinkering with, and have become
remarkably easy to approach as a hobbyist in recent years. Boards like the
TinyFPGA BX don’t require
any special hardware to use and can provide a simple platform for
modestly-scoped projects or just for learning.
While historically the software tools for programming FPGAs are proprietary and
provided by the hardware manufacturer, Symbiflow
(enabled and probably inspired by earlier work like Project
IceStorm) provides completely free and
open-source tooling and
documentation for programming some FPGAs, significantly lowering the cost of
entry (most vendors provide some free version of their design software but
limited to lower-end devices; a license for the non-free version of the software
is well into the realm of “if you have to ask, you can’t afford it”) and
appearing to yield better results in many cases.1
As somebody who finds it fun to learn new things and experiment with new kinds
of creations, FPGAs are quite interesting to me- they’re quite complex devices
that enable very powerful creations, with excellent depth for mastery. While I
did some course lab work with Altera FPGAs in university (and a little bit of
chip design/layout later), I’d call those mostly canned tasks with
easily-understood requirements and problem-solving approaches; it was sufficient
to familiarize myself with the systems, but not enough to be particularly
useful.
The announcement of Fomu
caught my interest because I was aware of the earlier Tomu
but wasn’t sufficiently interested to try to acquire any hardware. With Fomu
however, I’m rather more interested because it enables interesting capabilities
for playing with hardware- others have already demonstrated small
RISC-V CPUs running in that FPGA
(despite its modest logic capacity), for instance.
Even more conveniently for being able to play with Fomu, I’ve been in contact
with Mithro who is approximately half of the team
behind Fomu and gotten access to a stockpile of “hacker edition” boards that
have been hand-assembled but not programmed at all. With slightly early access
to hardware, I’ve been able to do some exploration and re-familiarize myself
with the world of digital logic design and figure out the hardware.
Previously as I was experimenting with logging the
temperature using a Raspberry Pi (to monitor the
temperatures experienced by fermenting cider), I noted that the Pi was something
of a terrible hack, and it should be possible to do more efficiently with some
slightly less common hardware.
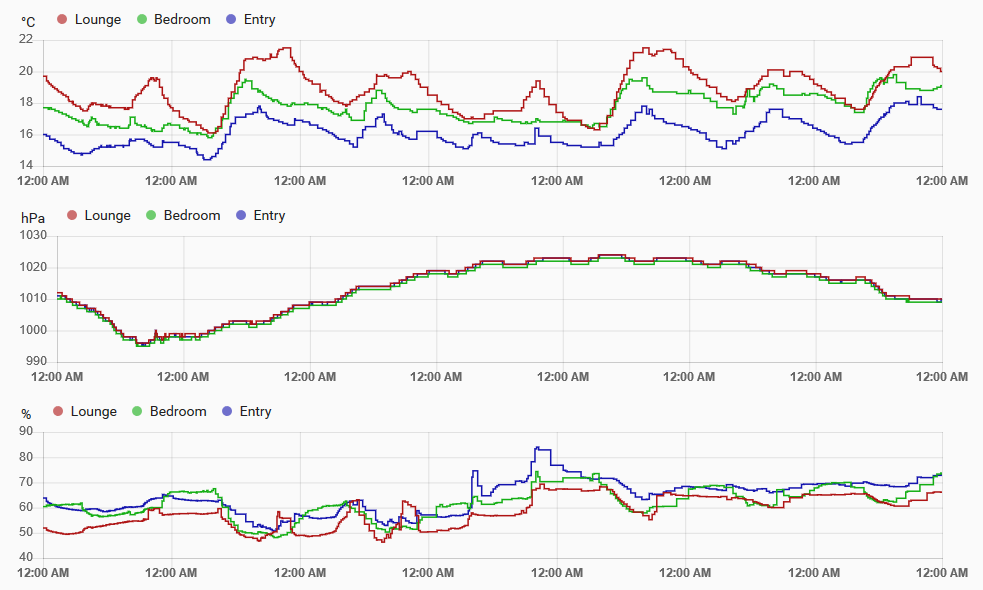
I decided that improved version would be interesting to build for use at home,
since it’s both kind of fun to collect data like that, and actually knowing the
temperature in the house is useful at times. The end result of this project is that
I can generate graphs like the one below of conditions around the house:
I had approximately the following exchange with a co-worker a few days ago:
Them: “Hey, do you have a spare Raspberry Pi
lying around?”
Me: [thinks] “..yes, actually.”
T: “Do you want to build a temperature logger with
Prometheus and a DS18B20+?
M: “Uh, okay?”
It later turned out that that co-worker had been enlisted by yet another
individual to provide a temperature logger for their project of brewing cider,
to monitor the temperature during fermentation. Since I had all the hardware at
hand (to wit, a Raspberry Pi 2 that I wasn’t using for anything and temperature
sensors provided by the above co-worker), I threw something together. It also
turned out that the deadline was quite short (brewing began just two days after
this initial exchange), but I made it work in time.
With the recent news that Crashplan were doing away with their “Home” offering, I had reason to reconsider my choice of online backup backup provider. Since I haven’t written anything here lately and the results of my exploration (plus description of everything else I do to ensure data longevity) might be of interest to others looking to set up backup systems for their own data, a version of my notes from that process follows.
The status quo I run a Linux-based home server for all of my long-term storage, currently 15 terabytes of raw storage with btrfs RAID on top. The choice of btrfs and RAID allows me some degree of robustness against local disk failures and accidental damage to data.
I’ve been enjoying The Legend of Zelda: Breath of the Wild recently, and reflected some on what makes it interesting to me from a non-gameplay perspective. This document is a version of those musings organized for publication, though perhaps less well organized than my usual writings- I am by no means a skilled critic, but spending longer in composing this would likely just delay its completion to little benefit.
Note that at the time of this writing I have not yet completed the game, but there are still some minor spoilers for the early portions of the game and general premise.
At the most recent Rust Sydney meetup (yesterday, “celebrating” Rust’s second birthday) I gave a talk intended to provide an introduction to using LLVM to build compilers, using Rust as the implementing language. The presentations were not recorded which might have been neat, but I’m publishing the slides and notes here for anybody who might find it interesting or useful. It is however not as illustrated as the title may seem to suggest.
It’s embedded below, or you can view standalone in your browser or as a PDF, available with or without presenter notes. Navigate with the arrow keys on your keyboard or by swiping.
A common belief among software engineers of a certain temperament seems to be that asynchronous I/O is the only way to achieve good performance in a server application.
There is also often confusion around async, since there are several ways in which it can appear:
Async I/O; eventing async keywords in languages often using Promises async as a keyword is often useful, though most frequently in the context of evented I/O under the hood. Promises or Futures are very useful when taking advantage of parallelism, but many applications don’t take any advantage of doing that kind of parallelism- they instead adopt async structures and their disadvantages through a cargo-cult assertion that doing so will make the programs fast.