markov.py
This was a little for-fun project that I built: a Python module/script that can be used to semi-randomly generate words, based on Markov chains.
Background, implementation
I was inspired by recalling the story of the Automated Curse Generator, which seemed like something that would be interesting to implement for fun in my own time, as it did indeed turn out to be. In short, the module examines input text and generates a graph with edges weighted based on character frequency, then traverses the graph to generate a word.
To generate the chains, the module builds a directed graph based on the seed text, where characters are linked to all the characters which are known to follow them, with edges weighted according to the percentage of all following characters any particular character consists of. For example, the string “zezifadi r00lz dr” would generate the following graph, where the value of each edge is the probability of choosing that edge to leave the associated vertex:
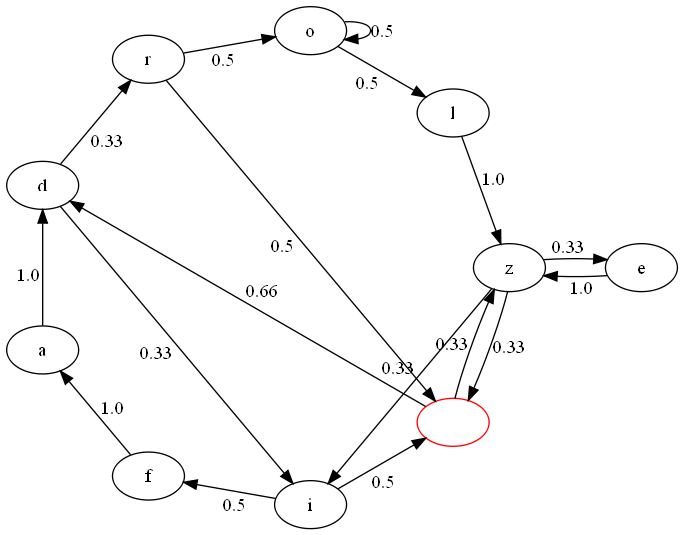
To generate a word, then, it can be as simple as starting at ’ ’ (the red node) and continuing to traverse the graph until another ’ ’ is encountered. In reality, while that worked, it was awfully boring. When seeded with some text in English, there was a disappointing number of short, boring (not to mention unpronounceable) words and far too few amusing longer ones. Think ‘ad’ and ’s’ rather than ’throm'.
It was rather easy to generate more interesting words, however, by simply adding some word-length limits, defaulting to a minimum of 4 character and a maximum of 12, tunable via arguments to the word generation method of the map. Rather than blindly following edges, as long as the word generated is shorter than the minimum, any chaining result of ’ ’ will be ignored. When maximum length is reached, the word will be immediately terminated provided the current character has any connection to blank space. If not, generation continues until such a connection is found.
What makes this so entertaining, I think, is its versatility. Since word generation is based entirely on the character frequency statistics of the input text, it works for any language. By extension, that means it could be easily be made to generate whole phrases in $(East-Asian language of your choice) by feeding it ideographs rather than Latin characters (ばかです1), or just nonsense that pronounces a lot like Simlish by putting in some other Simlish nonsense.
The script
Having implemented word generation in the module, it was reasonably short work to wrap the whole thing in a script so it could be invoked from the command line for great lulz. Something like the following does a decent job of providing amusement by generating a word every 15 seconds. For more fun, pipe the output into a speech synthesizer.
Tari@Kerwin ~ $ while markov.py; do sleep 15; done
Of course, before anything can be generated, a graph must be generated, which can be done via the -s option on the script or by invoking the addString method of MarkovMap. Quick example:
Tari@Kerwin ~ $ # Add the given string to the current graph, or to a new one.
Tari@Kerwin ~ $ markov.py -s"String to seed with" -ffoo.pkl
IO error on foo.pkl, creating new map
seeeeed
Tari@Kerwin ~ $ # Add some Delmore Schwartz to the map via stdin
Tari@Kerwin ~ $ markov.py -ffoo.pkl -s- << EOF
> (This is the school in which we learn...)
>What is the self amid this blaze?
>What am I now that I was then
>Which I shall suffer and act again,
>The theodicy I wrote in my high school days
>Restored all life from infancy,
>The children shouting are bright as they run
>(This is the school in which they learn...)
>Ravished entirely in their passing play!
>(...that time is the fire in which they burn.)
>EOF
idagheam
Tari@Kerwin ~ $ # Generate a word from the default graph in file markov.pkl
Tari@Kerwin ~ $ markov.py
awaike
Tari@Kerwin ~ $
Easy enough. I’ve found that a Maori seed (via Project Gutenburg) makes for some of the more easily pronounced words, but any language will (mostly) generate words that are pronounceable via that language’s pronunciation rules.
For seeding with non-Latin character sets, the script can take the -l or –lax option (‘strict’ keyword parameter to MarkovMap.addString()), which removes the restriction keeping graphed characters as only alphabetic. The downside, then, is that everything in the input is mapped out, so you’re much more likely to get garbage out unless the input is carefully sanitized of punctuation and such (GIGO, after all).
Code
Enough talk, I’m sure you just want to pick apart my code and play with nonsense words at this point. Download link is below. I’m providing the code under the Simplified BSD License so you’re allowed to do nearly anything with it, I just ask that you credit me for it in some way if you reuse or redistribute it.
-
Yes, I’m aware this is actually kana. ↩︎